









This post introduces the development of Kubernetes multi-cluster management and existing multi-cluster solutions. It also shares how KubeSphere distributes and deploys applications in a unified manner using KubeFed in hybrid cloud for the purpose of achieving cross-region high availability and disaster recovery. Finally, it discusses the possibility of decentralized multi-cluster architecture.
Before initiating KubeSphere v3.0, we made a survey in the community and found that most of the users called for multi-cluster management and application deployment in different cloud environments. To meet users' needs, we added the multi-cluster management feature in KubeSphere v3.0.
Kubernetes Architecture in a Single Cluster
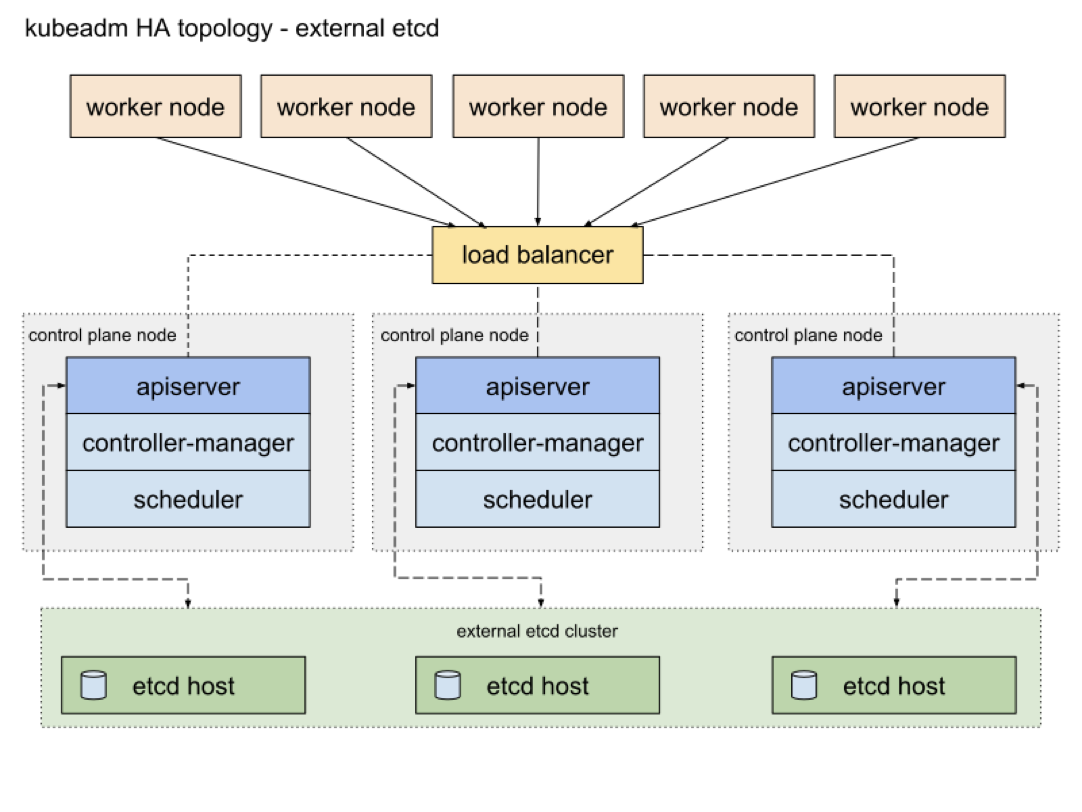
Kubernetes consists of the master and worker nodes. On the master node, the API server processes API requests, Controller Manager takes charge of starting multiple controllers and consistently coordinating the transition of declarative APIs from spec to status, Scheduler is used to schedule Pods, and etcd stores data of clusters. The worker nodes are mainly responsible for starting Pods.
Enterprises have the following expectations, which cannot be met by a single cluster:
Physical isolation: Despite the fact that Kubernetes supports isolation by namespace, and you can set the CPU and memory usage of each namespace, and also use the network policy to configure network connectivity among namespaces, enterprises still need a completely isolated physical environment to make sure that services are independent from each other.
Hybrid cloud: To reduce the cost, enterprises expect a package of public cloud providers and private cloud solutions to prevent vendor lock-in.
Multi-site high availability for applications: To make sure that applications still work properly even though an electricity power outage occurs in a region, enterprises expect to deploy multiple replicas in clusters in different regions.
Independent development, test, and production environment: Enterprises want to separately deploy the development, test, and production environments in different clusters.
Scalability: A single cluster has a limited number of nodes, while multiple clusters are more scalable.
The most common practice is to manage different clusters using multiple Kubeconfig files, and the frontend makes multiple API calls to simultaneously deploy services. However, KubeSphere manages clusters in a more cloud native way.
We researched existing solutions, which mainly focus on the following:
Resource distribution on the control plane, such as Federation v1 and Federation v2 launched by the Kubernetes community and Argo CD/Flux CD (distributed application pipelines).
Network connectivity between Pods in different clusters, such as Cilium Mesh, Istio Multi-Cluster, and Linkerd Service Mirroring. As these projects are bound to specific CNI and service governance components, I'll only detail Federation v1 and Federation v2 in the following sections.
Federation v1
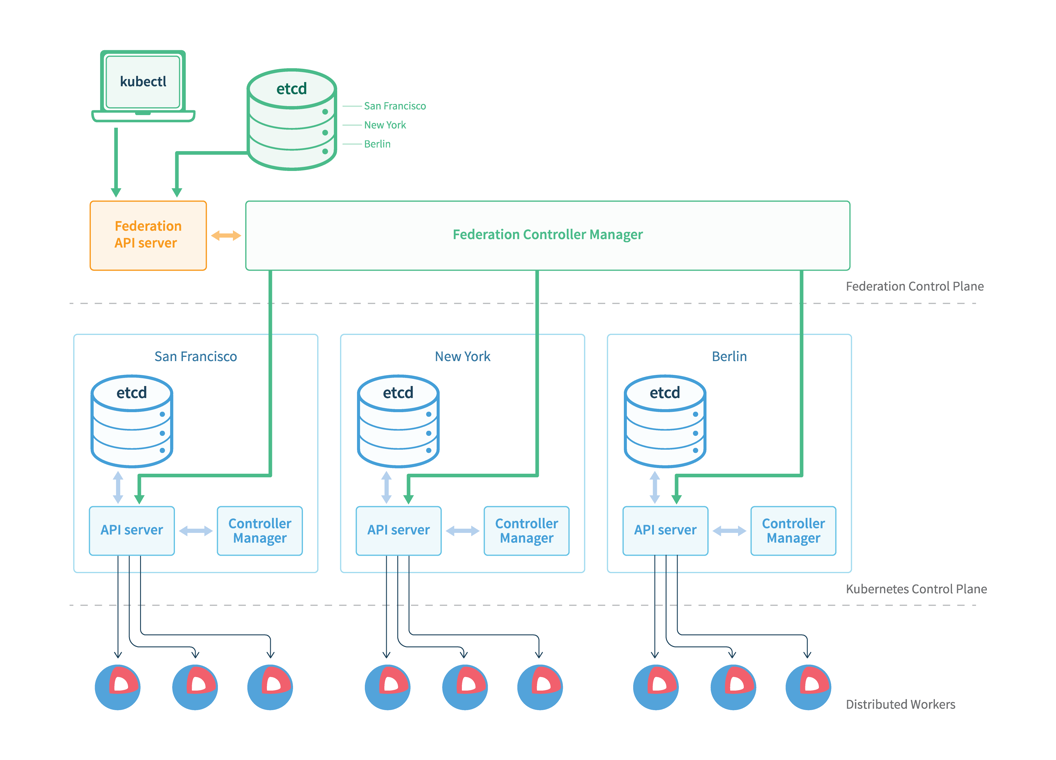
In the architecture of Federation v1, we can find that more than one API server (developed based on Kube-Apiserver) and Controller Manager (similar to Kube-Controller-Manager) exist. The master node is responsible for creating resource distribution tasks and distributing the resources to the worker nodes.
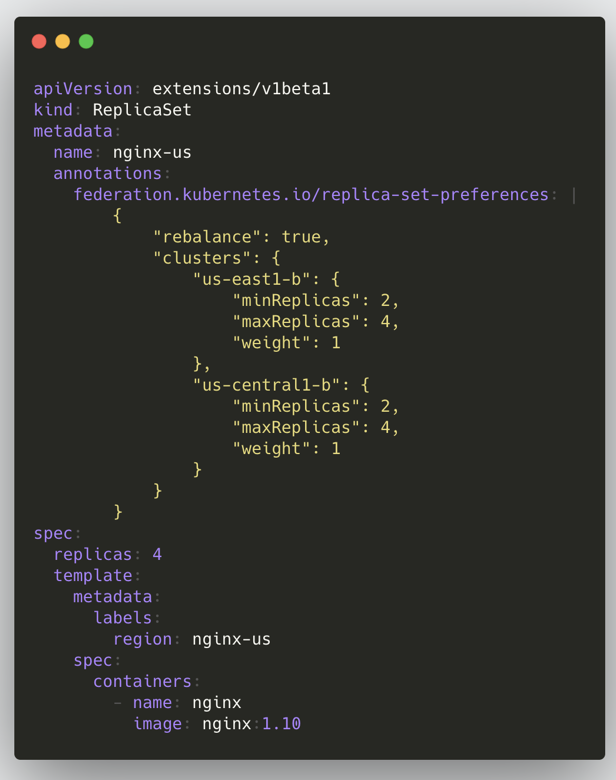
The previous figure shows configurations of creating ReplicaSets in Federation v1, and it can be seen that there are more annotations, which store logics of distributed resources. Federation v1 has the following drawbacks:
It introduces independently developed API servers, requiring extra maintenance.
In Kubernetes, an API is defined by Group/Version/Kind (GVK). Federation v1 only supports specific native Kubernetes APIs and GVKs, resulting in poor compatibility among clusters with different API versions.
Federation v1 does not support role-based access control (RBAC), making it unable to provide cross-cluster permission control.
Annotations-based resource distribution makes APIs too cumbersome.
Federation v2
The Kubernetes community developed Federation v2 (KubeFed) on the basis of Federation v1. KubeFed adopts the CRD + Controller solution, which does not introduce extra API sever and does not break into native Kubernetes APIs.
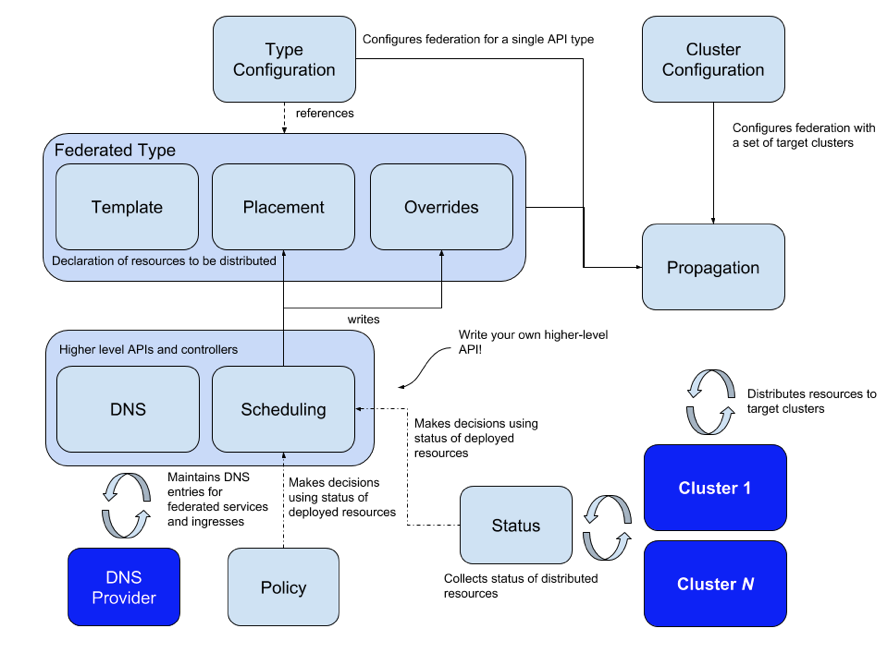
In the architecture of KubeFed, we can find that a custom resource definition (CRD) consists of Template, Override, and Placement. With Type Configuration, it supports APIs with different versions, which improves cluster compatibility. Moreover, it supports federation of all resources, including CRDs, service discovery, and scheduling.
The following exemplifies federated resources. Deployment in KubeSphere corresponds to FederatedDeployment in KubeFed. template in spec refers to the original Deployment resource, and placement refers to clusters where the federated resources need to be placed. In overrides, you can set parameters for different clusters, for example, you can set the image tag of each deployment and replicas in each cluster.
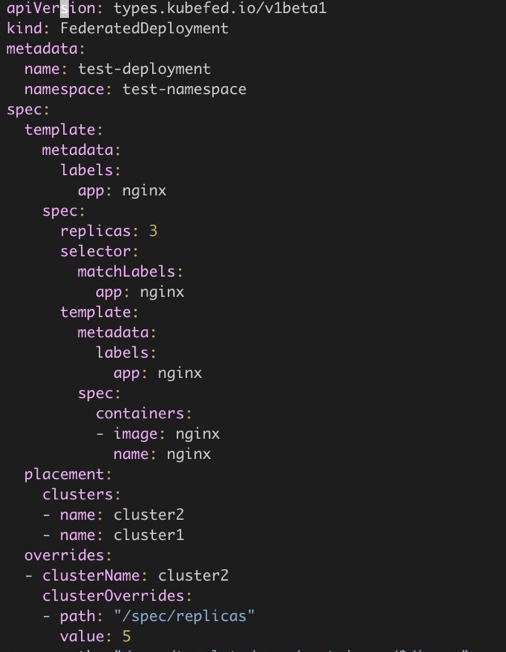
However, KubeFed also has the following limitations:
Its APIs are complex and error-prone.
No independent SDKs are provided, and binding and unbinding clusters rely on kubefedctl.
It requires the network connectivity between the control plane cluster and the managed clusters, which means that APIs must be reconstructed in a multi-cluster scenario.
The earlier versions cannot collect status information about federated resources.
KubeSphere on KubeFed
Next, I'll show you how KubeSphere implements and simplifies multi-cluster management on the basis of KubeFed.
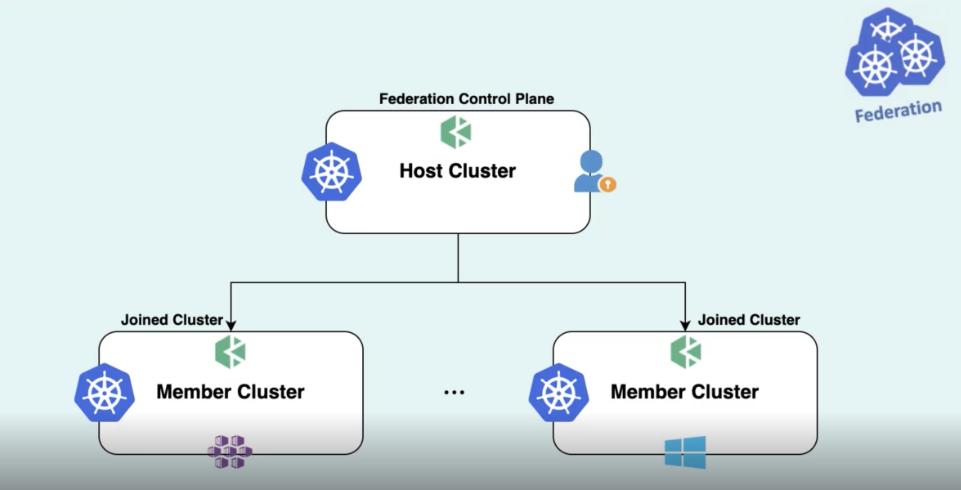
In the previous figure, the host cluster refers to the cluster with KubeFed installed, and it acts as the control plane; and the member cluster refers to the managed cluster. The host and member clusters are federated.
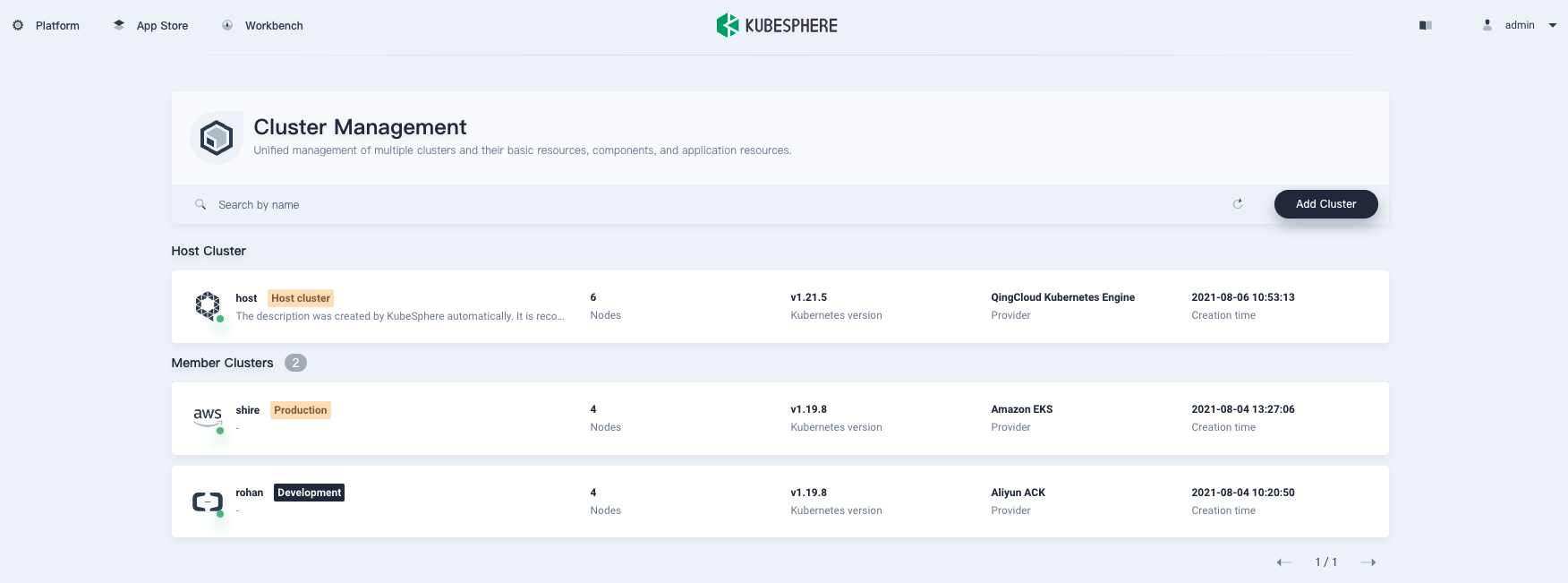
It can be seen that users can manage multiple clusters in a unified manner. KubeSphere defines a Cluster Object, which extends Cluster Objects of KubeFed, for example, the region zone provider.
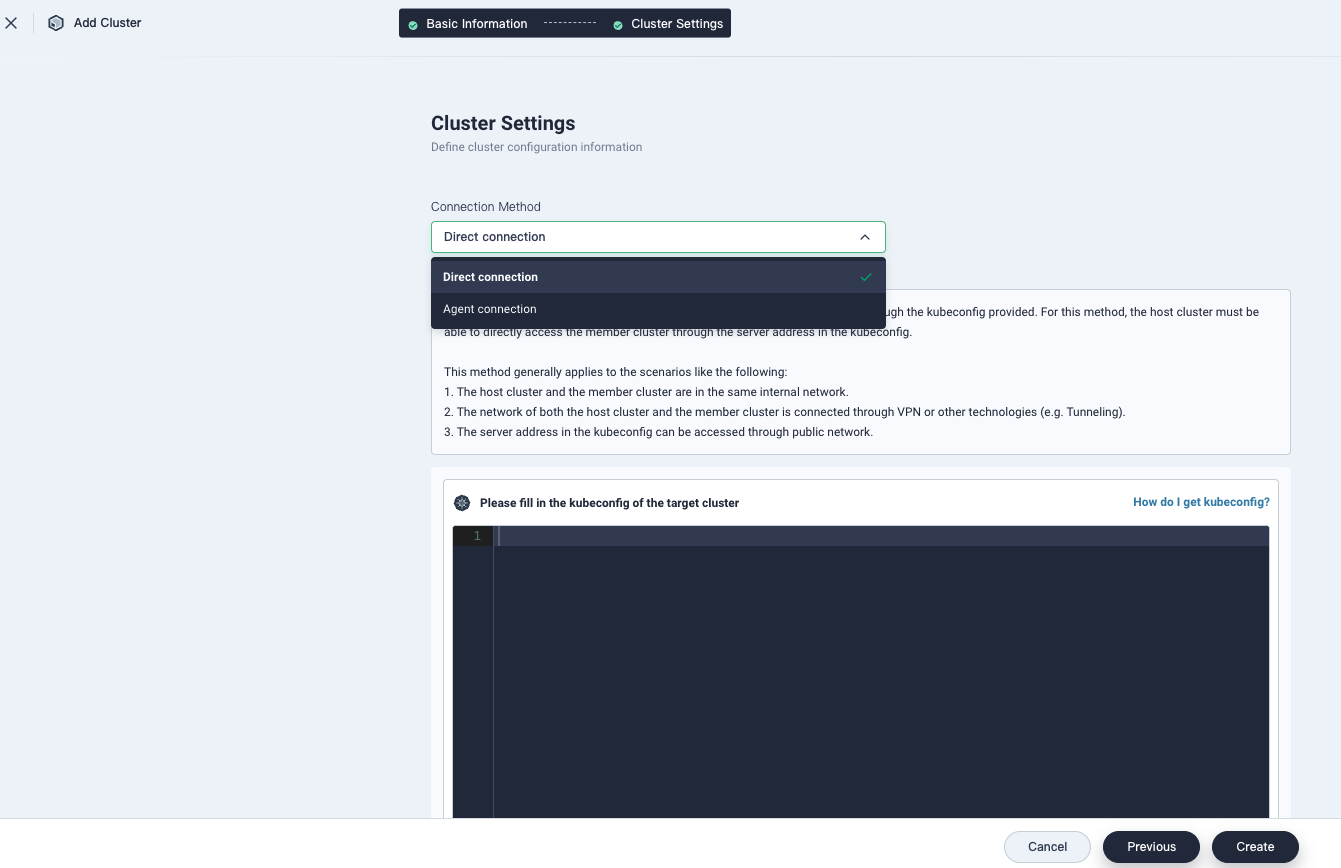
KubeSphere allows you to import clusters in the following ways:
- Direct connection
In this case, the network between the host cluster and member clusters must be accessible. All you have to do is to use a Kubeconfig file to add the target clusters without using the complex kubefedctl.
- Agent connection
If the network between the host cluster and member clusters is not accessible, KubeFed cannot support federation. Based on Chisel, KubeSphere makes Tower open source, so that users only need to create an agent to federate clusters on private cloud.
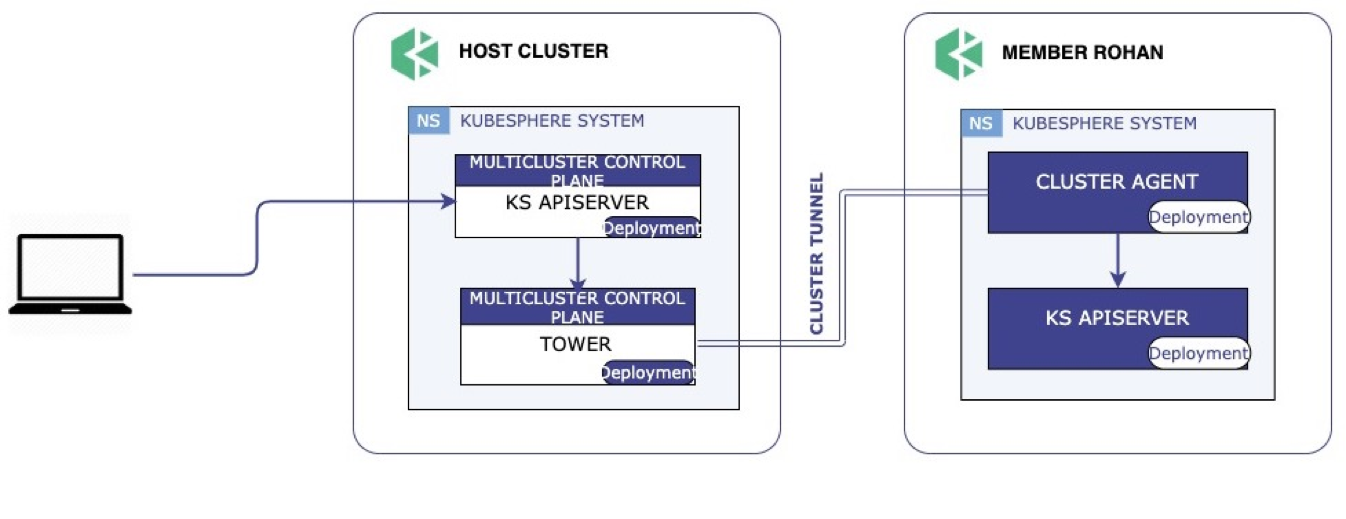
The workflow of Tower is as follows: (1) After you create an agent in a member cluster, the member cluster will connect to the Tower server of the host cluster; (2) The Tower server then listens to the port previously assigned by Controller and establishes a tunnel to distribute resources from the host cluster to the member cluster.
Support Multi-tenant in Multi-cluster Scenarios
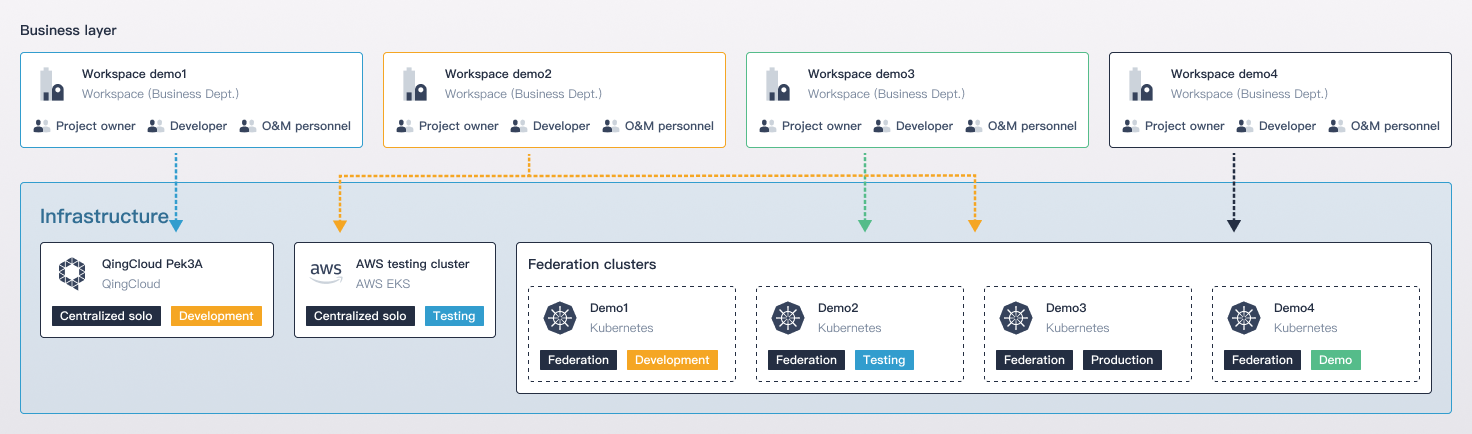
In KubeSphere, a tenant is a workspace, and CRDs are used to implement authorization and authentication of tenants. To make KubeFed to be less dependent on the control plane, KubeSphere delegates CRDs through the federation layer. After the host cluster receives an API request, it directly forwards the request to member clusters. Even the host cluster fails, the original tenant information is stored on the member clusters, and users can still log in to the console of the member clusters to deploy their services.
Deploy Applications in Multi-cluster Scenarios
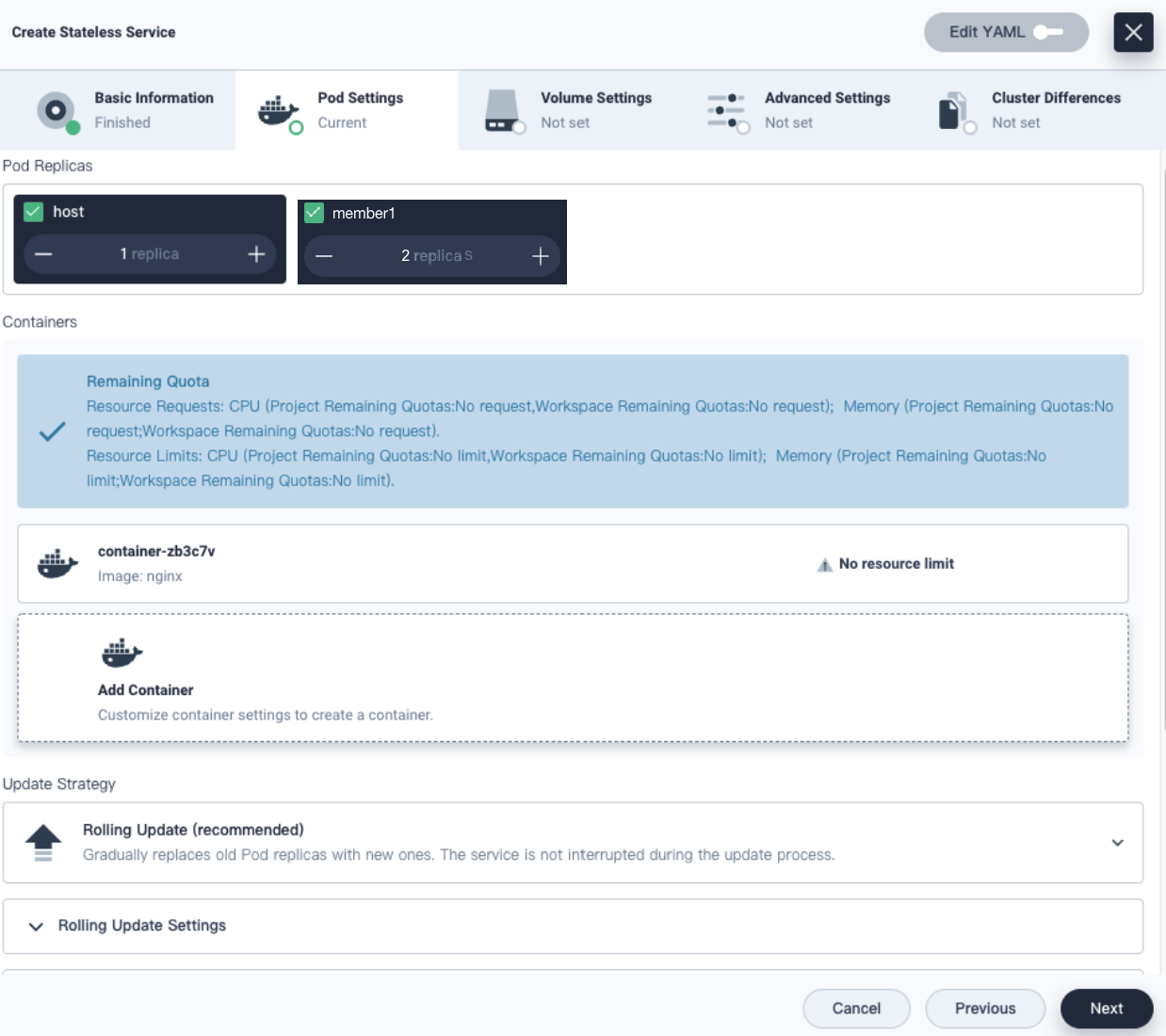
It is complex and error-prone if we manually define KubeFed APIs. When we deploy applications on KubeSphere, we can directly select the cluster where the application is to be deployed and specify replicas, and configure image address and environment variables of different clusters in Cluster Differences. For example, if cluster A cannot pull the gcr.io image, you can use the DockerHub address.
Collect Status Information About Federated Resources
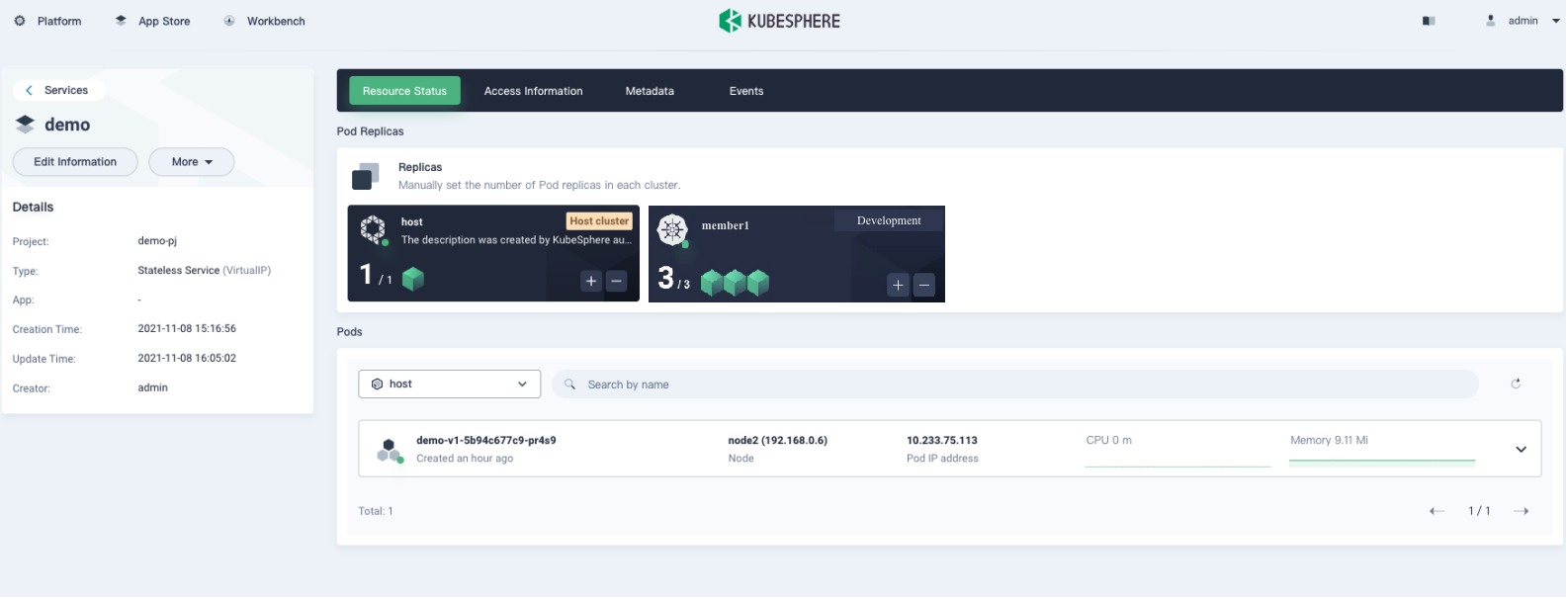
As we mentioned before, KubeFed cannot collect status information about federated resources. But don't worry, KubeSphere is always ready to help you. With our self-developed status collection tool, you can easily locate the event information and troubleshoot the failure, for example, when Pod creation fails. Moreover, KubeSphere can also monitor federated resources, which enhances observability.
Planned Improvements of KubeSphere
Although KubeSphere simplifies federation among clusters on the basis of KubeFed, it also needs improvements.
On the centralized control plane, resources can only be distributed using the push strategy, which requires that the host cluster must be highly available. Kubefed community is exploring a new possibility, that is, pulling resources from the member cluster to the host cluster.
KubeSphere is an open community, and we hope that more users can join us. However, multi-cluster development needs developers to define a series of Types CRDs, which is not developer-friendly.
No ideal service discovery solutions are available in multi-cluster scenarios.
Currently, KubeSphere does not support Pod replica scheduling in multi-cluster scenarios. In the next version, we plan to introduce Replica Scheduling Preference.
If you ask me whether it is possible to avoid introducing a centralized control plane and reducing the number of APIs in a multi-cluster scenario, my answer is definitely Liqo. But before we dig into Liqo, I'd like to introduce Virtual Kubelet first.
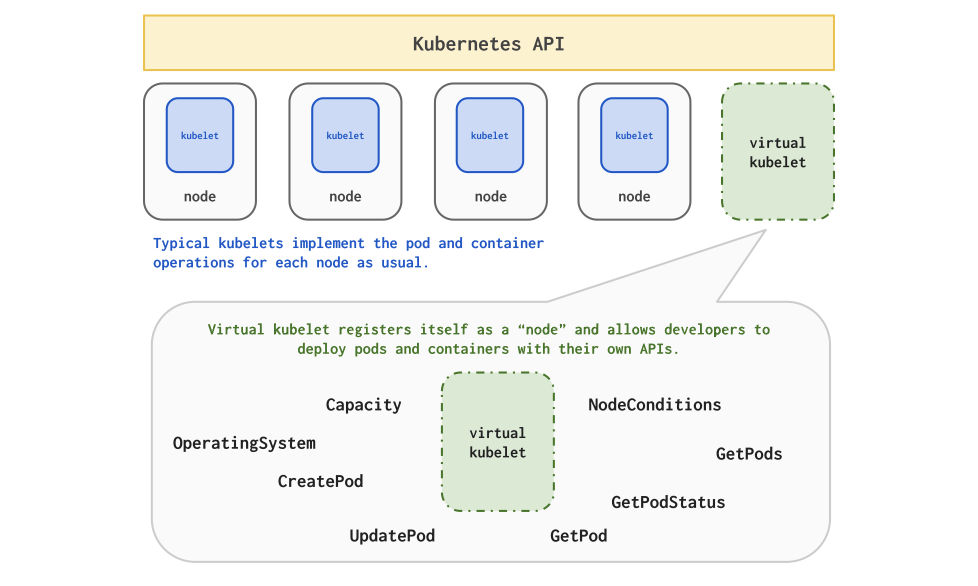
Virtual Kubelet allows you to simulate a Kubelet in your service as a Kubernetes node to join a Kubernetes cluster, making Kubernetes clusters more scalable.
![]()
In Liqo, clusters are not federated. In the figure on the left, K2 and K3 clusters are the member clusters of K1 under the Kubefed architecture, and the resources distribution needs to be pushed by K1. In the figure on the right, K2 and K3 are just a node of K1. In this case, when we deploy applications, we don't need to introduce any API, K2 and K3 seem to be nodes of K1, and the services can be smoothly deployed to different clusters, which greatly reduces the complexity of transforming from a single cluster to multiple clusters. However, Liqo is still at its early stage and currently does not support topologies with more than two clusters. KubeSphere will continuously follow other open-source multi-cluster management solutions to better satisfy your needs.
