









作者:任建伟,某知名互联网公司云原生工程师,容器技术信徒,云原生领域的实践者。
背景介绍
在接触容器化之前,我们团队内部的应用一直都是基于虚拟机运管,由开发人员自行维护。
由于面向多开发部门服务,而开发人员运维能力参差不齐,所以每次部署新的环境时往往都要耗费大量时间。
针对部署难的问题,我们将部分组件、服务容器化,采用 Docker 发布管理解决了部分问题,但仍未降低对开发人员的运维技能要求。
下面是我们基于虚拟机管理开发环境的流程:
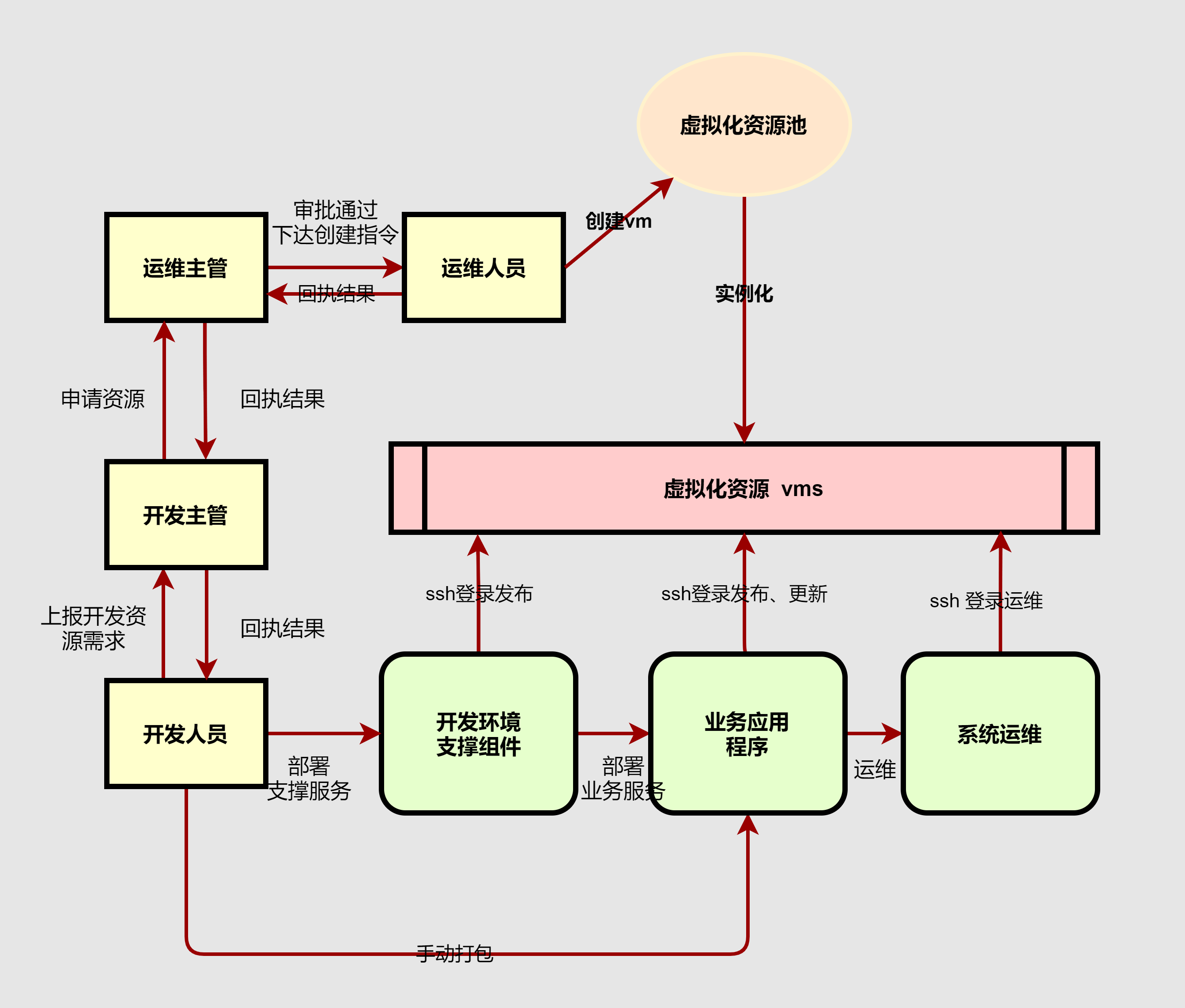
从上图中我们也能发现当前架构存在的问题:
- 下发虚机由各部开发人员管理,虚机安全问题难以维护、保障;
- 基于
shell运维,专业性过强; - 基于手动打包、发布,耗时耗力且不可靠。
选型说明
针对上述提到的痛点,我们决定对运维架构进行改造。新建运管平台,技术选型整体基于云原生,优先选取 CNCF 项目。
Kubernetes 成为了我们平台底座的不二选择, 但 Kubernetes 原生的 Dashboard 不太满足实际使用需求。
而从头开发一套 workbench 又耗时耗力,由此我们目光转向了开源社区。
此时,一个集颜值 + 强大功能于一身的开源项目进入我们视野。是的,它便是 KubeSphere。
而 KubeSphere 愿景是打造一个以 Kubernetes 为内核的云原生分布式操作系统,它的架构可以非常方便地使第三方应用与云原生生态组件进行即插即用(plug-and-play)的集成,支持云原生应用在多云与多集群的统一分发和运维管理。
对于 KubeSphere 能否作为部署平台,最终结论如下:
KubeSphere 虽功能强大,但更适合作为管理端使用,不太适合面向普通用户。
我们需要本地化一套 workbench ,简化部分功能,屏蔽专业性术语(如工作负载、容器组、安全上下文等)。
本地化部分内容如下:
- 基于企业空间、命名空间,本地化租户、工作空间的概念,一个租户(企业空间)可管理一个到多个工作空间(命名空间),并接入独立用户体系。
- 本地化应用发布流程: 由拆分的应用发布流程(构建镜像+创建负载),本地化为:创建应用 -> 上传 jar -> 指定配置 -> 启动运行的串行流程。
- 本地化链路监控:构建镜像预先埋点,创建应用时选择是否开启链路追踪。
- 本地化配置、应用路由等,添加版本管理功能。
事实上,我们本地化的重点是应用管理,但是 KubeSphere 功能过于强大、特性过于灵活,导致配置起来项过于繁琐。
针对部分配置项我们采用设置默认值的方式,而非交由用户去配置。(比如:容器安全上下文、同步主机时间、镜像拉取策略、更新策略、调度策略等)
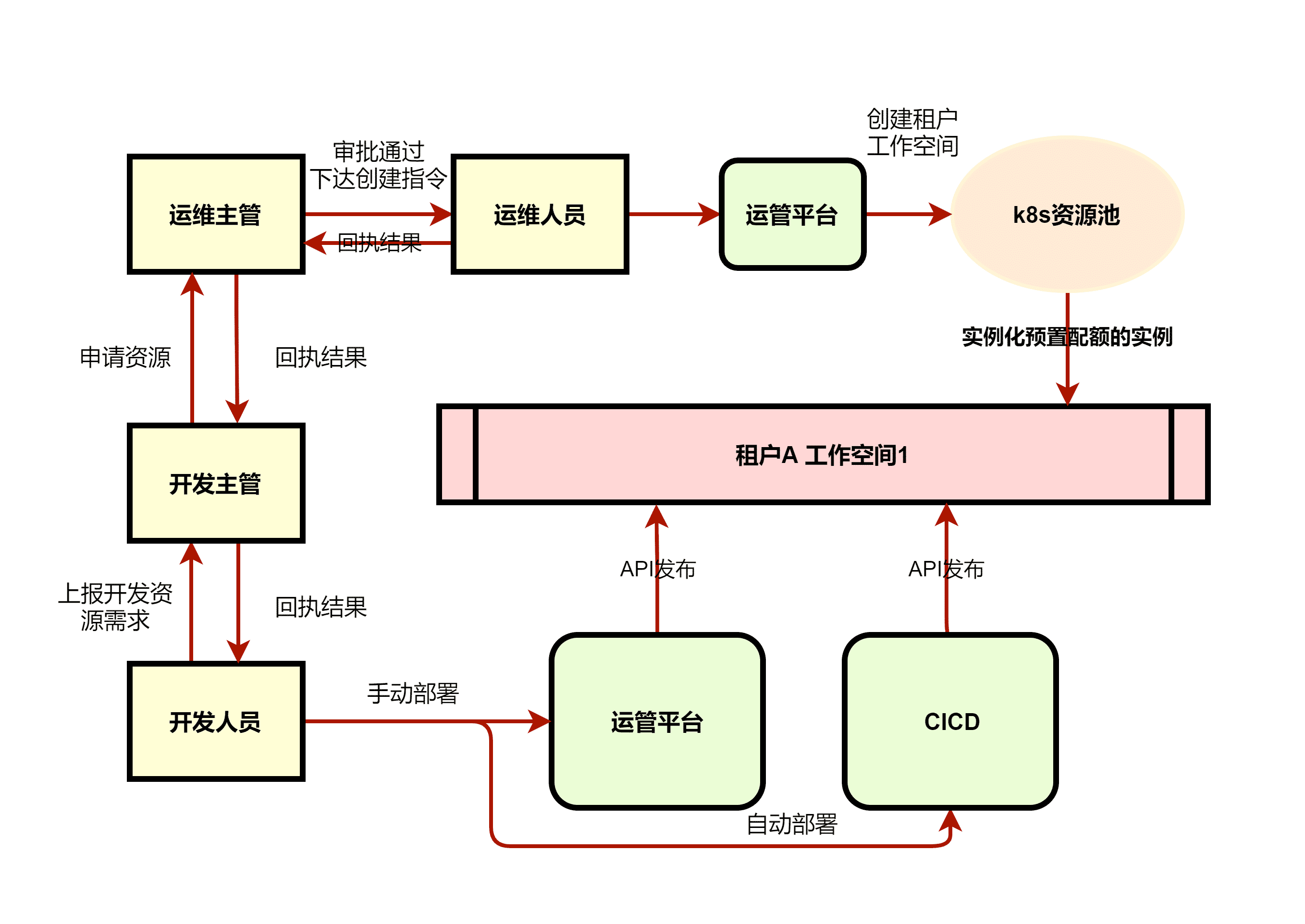
改造后的运维架构如下:
实践过程
基于 KubeSphere 的运管平台整体架构如下:
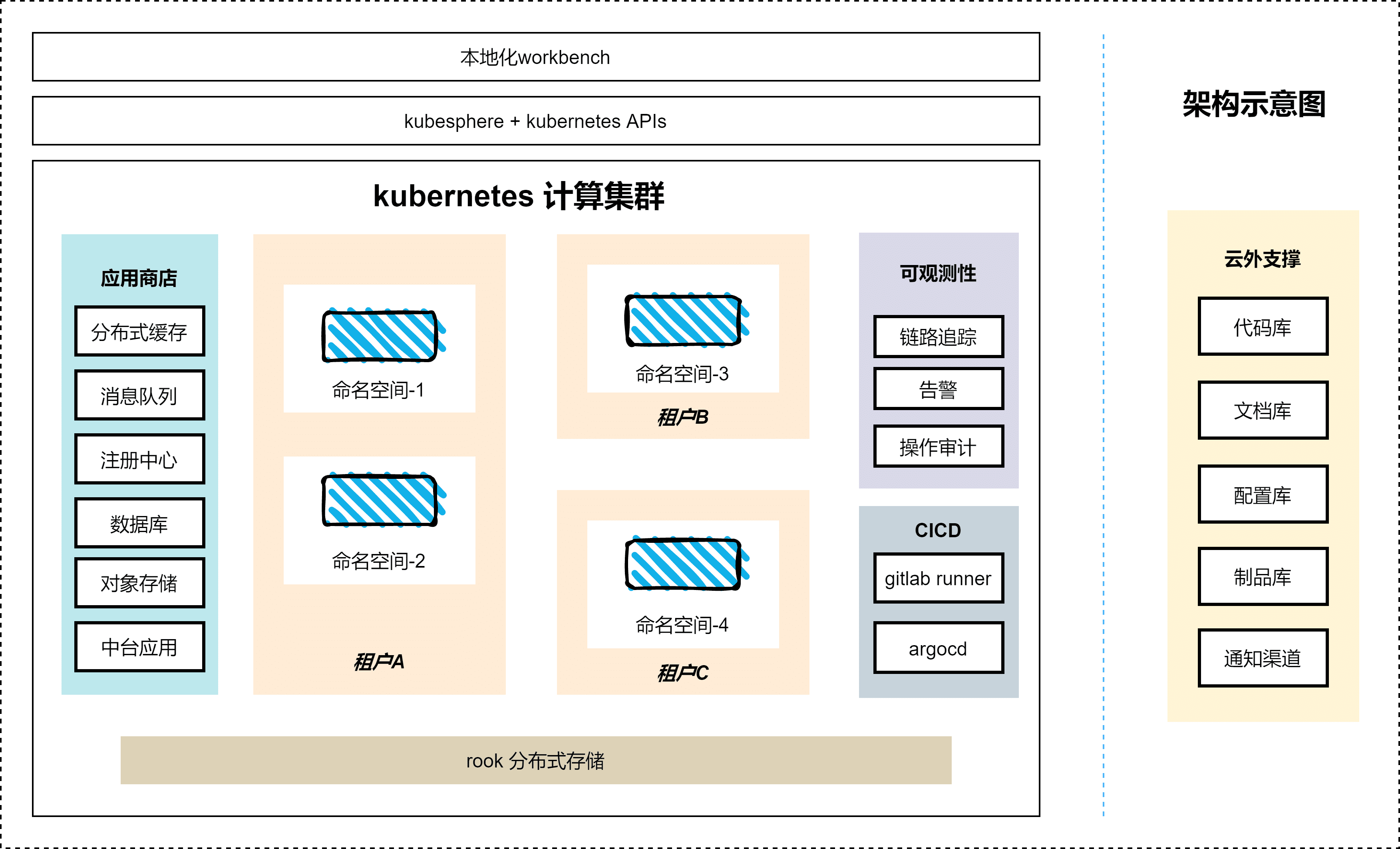
环境信息表:
| 名称 | 版本 | 说明 |
|---|---|---|
| kukekey | v1.0.1 | KubeSphere 安装工具 |
| kubesphere | v3.0.0 | 基于 K8s 的面向云原生应用的分布式操作系统 |
| kuberentes | v1.18.6 | 容器编排系统 |
| docker | v19.03.15 | 容器引擎 |
| CentOS | 7 | 操作系统 |
| kernel | 5.4 | 操作系统内核 |
本地化部署流程如下:
镜像本地化
1️⃣ 基于 harbor 搭建私有镜像库。

2️⃣ 离线下载并上传 kubesphere 依赖镜像至私有 harbor 内,project 名称保持不变。
3️⃣ 本地化 B2I 基础镜像,本地化如下内容:
- 内置 Arthas,便于调试;
- 内置 SkyWalking Agent 用于集成链路追踪;
- 内置 Prometheus Agent 用于指标监控;
- 添加
windows字体。
4️⃣ 本地化应用商店初始化镜像(openpitrix/release-app)。
由于预置的 chart 有很多我们实际并未使用,所以我们删除预置了 chart ,并导入实际所需 chart (包括本地化的中间件 chart 、中台 chart)
5️⃣ 镜像 GC。
针对频繁构建的 repo ,配置合理的 GC 策略:

搭建 K8s
基于 KubeKey 1.0.1 部署了三主多从节点 K8s v1.18.6 集群:
搭建 Rook 集群
使用 KubeKey 1.0.1 新增三个存储节点并打上污点标签,搭建 Rook 集群
对于存储的替换主要出于以下方面考虑:
- 有 Ceph 裸机部署使用经验;
- 对比默认存储 OpenEBS Local PV,Rook 支持多存储类型;
- Rook 为 CNCF 毕业项目。
搭建 KubeSphere 平台
基于 KubeKey 1.0.1 部署了 KubeSphere,未作本地化修改。
CI/CD 实践
CI/CD 部分我们并没有使用 KubeSphere 提供的流水线功能,而是选择 gitlab-runner + ArgoCD 方案。
CI 实现
CI 部分利用 gitlab-ci 切换构建时特性,我们抽象出了 provider 概念。provider 本质为工具 / 程序的容器化封装,提供某一方面能力了。如:
- maven-provider:
java程序构建时环境,内置私有nexus配置; - npm-provider:
nodejs程序构建时环境,内置私有npm源配置; - email-provider:
smtp交互程序,用于邮件通知; - chrome-headless-provider: 浏览器截屏。
使用时,只需引用并传递相应参数即可:
variables:
AAA: xxx
BBB: yyy
stages:
- build
- scan
- email
build:
stage: build
image: harbor.devops.io/devops/maven-provider
tags:
- k8s-runner
script:
- mvn clean package
only:
refs:
- develop
changes:
- src/**/*
scan:
stage: scan
image: harbor.devops.io/devops/sonar-provider
tags:
- k8s-runner
script: xxx
rules:
- if: '$CI_PIPELINE_SOURCE == "schedule"'
email:
stage: email
image: harbor.devops.io/devops/sendmail
tags:
- k8s-runner
script:
- /work/send-mail sonar --email-to=$EMAIL_TO_LIST --email-cc=$EMAIL_CC_LIST --sonar-project-id=$PROJECT_NAME --sonar-internal-url=$SONAR_INTERNAL_ADDR --sonar-external-url=$SONAR_EXTERNAL_ADDR
rules:
- if: '$CI_PIPELINE_SOURCE == "schedule"'
CD 实现
CD 部分,我们利用 chart 对应用进行定义,并将 chart 剥离于开发库,独立于配置库进行管理,用于 ArgroCD 同步。
对于配置库与开发库分离,主要出于以下考虑:
- 清晰分离了应用程序代码与应用程序配置。
- 更清洁的审计日志:出于审计目的,只保存配置库历史更改记录,而不是掺有日常开发提交的日志记录。
- 访问的分离:开发应用程序的开发人员不一定是能够 / 应该推送到生产环境的同一个人,无论是有意的还是无意的。 通过使用单独的库,可以将提交访问权限授予源代码库,而不是应用程序配置库。
- 自动化
CI Pipeline场景下,将清单更改推送到同一个Git存储库可能会触发构建作业和Git提交触发器的无限循环。 使用一个单独的repo来推送配置更改,可以防止这种情况发生。
角色划分
角色方面,我们定义了三种类型角色,职责如下:

使用效果
通过引入 KubeSphere 平台以及 CI/CD,效率提升明显:
- 计算资源池化,不再下发虚机,计算资源统一运管;
- 基于容器化的流水线构建、发布应用,保障了构建的可靠性,同时解放双手;
- 基于本地化
workbench运维,由于屏蔽了专业性词汇术语,降低使用者学习成本。日志查看、应用更新等操作更为便捷; - 针对角色的划分,使得运维边界清晰,责任明确。
问题 & 解决
在一年多的容器平台使用过程中,我们遇到了蛮多的小问题,这里我举几个有代表性的例子:
B2I 没有清理策略
存在问题:
在使用 kubesphere v3.0 的过程中我们发现:不断通过 B2I 构建应用,会产生大量的 B2I 任务记录,并且 minio 内上传的程序包文件越来越多,且并没有相应的清理策略。
解决方案:
开发定时 job , 定期进行清理。
内核版本过低,导致容器相关漏洞的发生
存在问题:
初期,我们使用 CentOS7 默认的 3.10 版本内核。
解决方案:
升级内核版本至 5.x。
链路追踪
存在问题:
KubeSphere 预装的 jaeger 不支持 dubbo 协议,无法对 dubbo 应用进行监控。
解决方案:
利用 SkyWalking 用于链路追踪,并在基础镜像内埋点。
报表相关服务缺少字体
解决方案:
将缺少 windows 字体安装至 B2I 基础镜像内。
- 路由集群外服务
由于部分应用部署于 K8s 外部,针对这部分应用我们选择 Endpoint + ExternalName + Ingress 的方式进行路由。

未来规划或展望
1️⃣ 有状态应用的 Operator 开发
当前有状态应用依赖 helm hook 管理, 且功能单一。
未来我们计划,针对常用有状态应用,开发对应 operator,提供创建、扩容、备份等常用功能。
2️⃣ CNI 迁移至 Cilium
选取 Cilium 替换 Calico 主要出于以下考虑 :
Cilium为CNCF毕业项目,活跃度高;Cilium基于eBPF实现,在粒度和效率上实现了对系统和应用程序的可观测性和控制;Cilium安全防护功能更强,提供了过滤单个应用协议请求的能力,例如 :- 允许所有使用
GET方法和/public/.*路径的HTTP请求,拒绝所有其他请求; - 允许
service1在Kafka主题topic1上生产,允许service2在topic1上消费,拒绝所有其他 Kafka 消息; - 要求
HTTP报头X-Token:[0-9]+出现在所有REST调用中。
- 允许所有使用
3️⃣ cri 由 Docker 替换为 Containerd
4️⃣ 容器文件浏览器功能开发
当前阶段,开发人员下载容器内文件的需求,只能由运维人员使用 kubectl cp 的方式协助获取,后续我们规划开发容器文件浏览器相应功能。
5️⃣ 容器宿主机系统替换为 rocky,以应对 CentOS 停止维护。
