




驭势科技
驭势科技UISEE 是中国领先的自动驾驶公司,致力于为全行业、全场景提供 AI 驾驶服务,交付赋能出行和物流新生态的AI驾驶员。

行业
自动驾驶
地点
北京、上海、浙江、深圳
云类型
公有云、私有云
挑战
高可用、多集群管理、监控及告警
采用功能
多集群及多租户管理、监控及告警
公司简介
驭势科技成立于 2016 年 2 月,坚持立足本土研发,根植中国市场。总部和研发中心设立在北京,在上海嘉定和浙江嘉善分别设有研发中心、研发试制和应用创新中心。此外,在深圳、广西、成都、武汉等地均设有业务分支机构。
驭势科技依托自主研发的 U-Drive 智能驾驶平台,在业务上已经形成可规模化部署的 L3-L4 级智能驾驶系统,可以满足多场景、高级别的自动驾驶需求。2019 年,驭势科技率先在机场和厂区实现了“去安全员”无人驾驶常态化运营的重大突破,落地“全场景、真无人、全天候”的自动驾驶技术,并由此迈向大规模商用。

行业背景
驭势科技(UISEE)是国内领先的自动驾驶公司,致力于为全行业、全场景提供 AI 驾驶服务,交付赋能出行和物流新生态的 AI 驾驶员。由于需要保障各个场景下 “真 · 无人”(即无安全员在车上或跟车)的业务运作,我们比较注重在 “云端大脑” 上做了一些保障其高可用和可观察性方面的实践。
让我们假设有这样一个场景:在一个厂区运行了几十台的无人物流拖车,考虑到 “真无人” 环境下的安全运营,我们会采取车云连接长时间断开(一般为秒级)即停车的策略;如果在运营的过程中,云端出现故障且缺乏高可用能力,这将造成所有车辆停运。显然这对业务运营会造成巨大影响,因此云平台的稳定性和高可用性是非常重要和关键的。
为什么选择 KubeSphere
我们和 KubeSphere 的结缘可以说是 “始于颜值,陷于才华”。早在 KubeSphere v2.0 发布之时,我们因缘际会在社区的新闻中留意到这个产品,并马上被它 “小清新” 的界面所吸引。于是,从 v2.0 开始我们便开始在私有云上进行小范围试用,并在 v2.1 发布之后开始投入到我们公有云环境的管理中使用。
KubeSphere v3.0 是一个非常重要的里程碑发布,它带来了 Kubernetes 多集群管理的能力、进一步增强了在监控和告警方面的能力,并在 v3.1 中持续对这些能力进行夯实。由此,我们也开始更大范围地将 KubeSphere 应用到我们自有的和客户托管的集群(及在其中运行的工作负载)的管理上,同时我们也在进一步探索如何将现有的 DevOps 环境和 KubeSphere 做整合,最终的目标还是希望将 KubeSphere 打造成我们内部面向云原生各应用、服务、平台的统一入口和集中管理的核心。
正是由于 KubeSphere 提供了这样优秀的管控能力,使得我们有了更多时间从业务角度去提升云平台的可用性。这次分享的两个内容就是我们早期和现在正在推进的两项可用性相关的实践。

提升多集群管理便捷性
降低监控告警维护成本
对于入门 K8s 非常友好
“高可用”实践:提供热备能力的 Operator
“高可用” 方面,我们期望解决的问题是如何确保云端服务出现故障时可以用最快的速度重新恢复到稳定运行的状态。
限定区域 L4 无人驾驶场景的 “高可用” 诉求
“高可用” 从时间量化的角度通常就是几个 9 级别选择,但落到具体的业务场景,所面临的问题和挑战却是各不相同的。如上图所列举的,对于我们 “限定区域 L4 无人驾驶场景” 而言,以 toB 业务为主所造成的客户私有云种类繁多、对于恢复过程容忍度不同、以及客户定制服务产生的历史包袱较多是制约我们构建高可用方案的几个主要问题。面对这些限制,我们选择了一个比较 “简单粗暴” 的思路,试图 “化繁为简” 跳出跨云高可用成本高、为服务附加高可用能力融合风险高的常见问题包围圈。

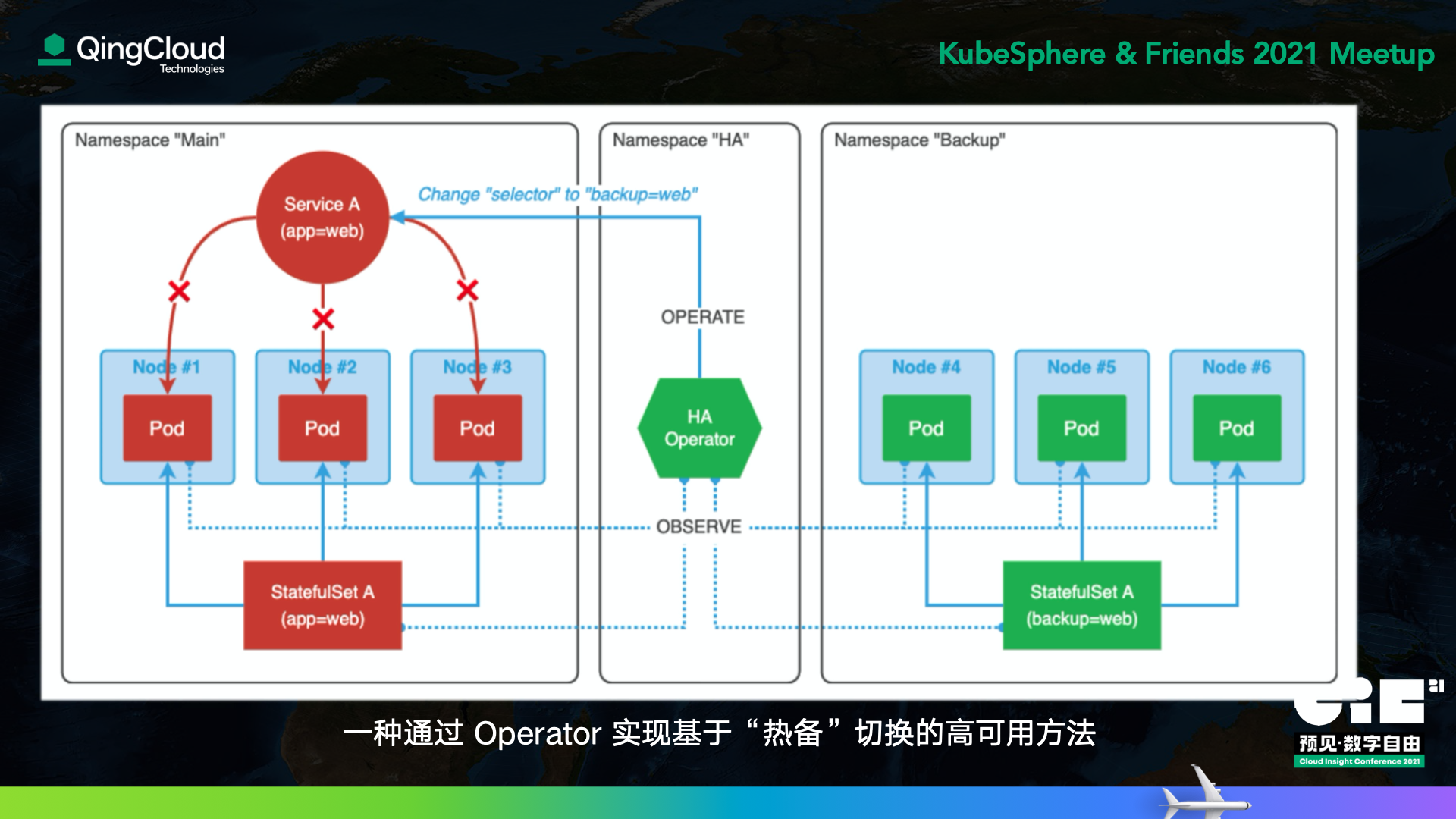
一种通过 Operator 实热备切换的高可用方法
如下图所示,这个方案的思路很直接 —— 实现服务 Pod 状态监测并在状态异常时进行主备 Pod 切换。如果我们从 Controller 的 “Observe - Analyze - Act” 体系来看,它做了如下工作:
- 监测。同时能够监测 Pod / Deployment / StatefulSet / Service 的变化(包括能够监控特定的 Namespace);监测到有变化则触发 Reconcile 调协过程(即以下两个操作)。
- 判断。遍历所有 Service,获取 Deployment / StatefulSet,将其 status 中的服务的总数量与可用数量进行比较;如果有副本不可用,则再遍历 dp/sts 里面的 Pod,通过容器的状态及重启次数来找到不健康的 Pod,当一个 dp/sts 下所有的 Pod 都不健康,则认为这个服务整体不健康。
- 切换。同一个服务部署主备两套 dp/sts,在当前服务的 dp/sts 指向的 Pod 全都不健康时(即整个服务不健康),若另一套 dp/sts 健康,切换至另一套 dp/sts。
在这个 Operator 的开发框架上,我们选用了 Kubernetes 官方社区的 Operator SDK,即 Kubebuilder。从技术上看,它对于编写 Controller 通常需要的核心组件 client-go 有比较好的封装,可以帮助开发者更专注于业务逻辑的开发;从社区的支持角度看,发展也比较平稳。
行百里者半九十:高可用功能落地的长尾在于测试
由于 “高可用” 功能的特殊性,它的测试尤其重要,但常规的测试手段可能并不是很适用(这里存在一个有意思的 “悖论”:测试是为了发现问题,而高可用的启用会避免发生问题)。所以我们在完成这个 Operator 的开发后,其实更多的时间是花在测试方面,在这里我们主要实施了三个方面的测试工作:
- 端到端的 BDD 测试。这块作为基础功能验证和测试,我们使用了支持 Cucumber BDD 测试框架的 Godog 项目(支持 Cucmber Gherkin 语法),BDD 也适合业务方直接导入需求。
- 针对运行环境的混沌测试。这块我们使用 ChaosBlade 对 Kubernetes 物理节点的系统运行环境进行相关混沌测试,以检验出现基建故障时的高可用表现。
- 针对业务层面的混沌测试。这里我们使用 Chaos Mesh 对主备服务进行 Pod 级别的测试,使用 Chaos Mesh 一方面是由于它在这个层面功能覆盖比较全面,另一方面也是因为它的 Dashboard 便于管理测试所用到的各项测试用例。

“可观察”实践:车云端到端 SkyWalking 接入
“可观察” 方面,我们期望解决的问题是在服务故障恢复后,如何确保我们能够尽可能快的定位到问题的根源,以便尽早真正消除问题隐患。
无人驾驶车云一体化架构下的 “可观察” 诉求
“车云一体化” 架构是无人驾驶的一个重要核心,从云端视角来看,它的一个巨大挑战就是业务链路非常长,远长于传统的互联网纯云端的业务链路。这个超长链路上任意一点的问题都有可能引发故障,轻则告警、重则导致车辆异常离线,所以对于链路上的点点滴滴、各式各样的信息我们总是希望能够应收尽收,以便于定位问题。同时,纯粹的日志类数据也是不够的,因为链路太长且又分布在车云的不同地方,单靠日志不便于快速定位问题发生的区间从而进行有针对性的问题挖掘。
为了便于大家更具象的了解链路之长,下图我们给出了一个抽象的 “车云一体化” 架构图,感兴趣的朋友可以数一下这 “7 x 2” 的调用链路。
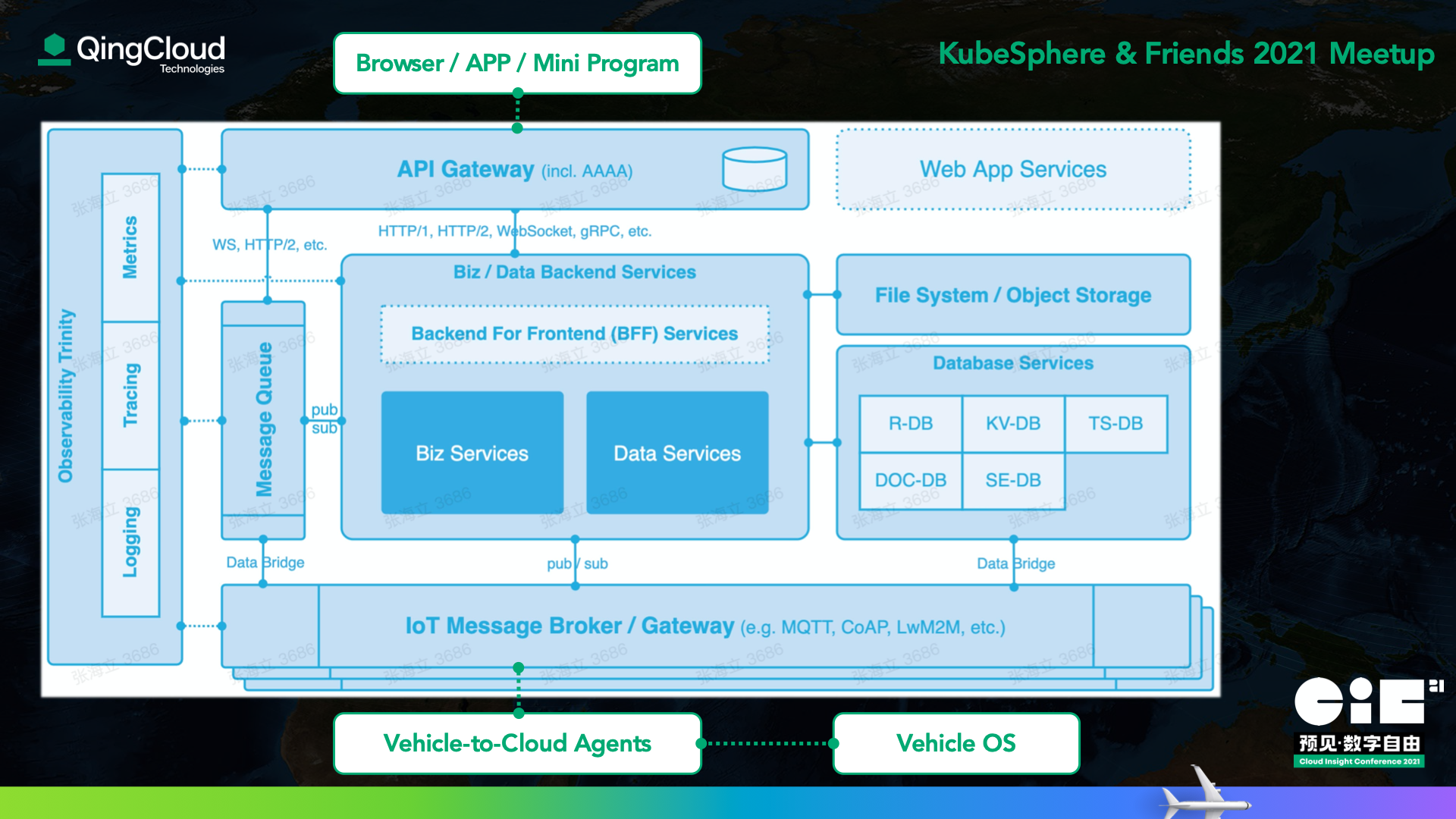
通过 SkyWalking 实现车云全链路追踪
Apache SkyWalking 是社区中一个优秀而且活跃的可观察性平台项目,它同时提供了 Logging、Metrics、Tracing 可观察性三元组的功能,其中尤以追踪能力最为扎实。为了方便大家对后续内容有更好的把握,这边也简单整理几个关键点供大家参考:
Trace:一个 Trace 代表一个潜在的,分布式的,存在并行数据或并行执行轨迹(潜在的分布式、并行)的系统。一个 Trace 可以认为是多个 Span 的有向无环图(DAG)。
Span:在服务中埋点时,最需要关注的内容。一个 Span 代表系统中具有开始时间和执行时长的逻辑运行单元。Span 之间通过嵌套或者顺序排列建立逻辑因果关系。在 SkyWalking 中,Span 被区分为:LocalSpan—服务内部调用方法时创建的 Span 类型;EntrySpan—请求进入服务时会创建的 Span 类型(例如处理其他服务对于本服务接口的调用);ExitSpan—请求离开服务时会创建的 Span 类型(例如调用其他服务的接口)。SkyWalking 中,创建一个 ExitSpan 就相当于创建了一个 Parent Span,以 HTTP 请求为例,此时需要将 ExitSpan 的上下文编码后,放到请求的 Header 中;在另一个服务接收到请求后,需要创建一个 EntrySpan,并从 Header 中解码上下文信息,以解析出它的 Parent 是什么。通过这样的方式,ExitSpan 和 EntrySpan 就可以串联在一起。SkyWalking 中未对 ChildOf 和 FollowsFrom 两种类型的 Span 作区分。
TraceSegment:SkyWalking 中的概念,介于 Trace 和 Span 之间,是一条 Trace 的一段,可以包含多个 Span。一个 TraceSegment 记录了一个线程中的执行过程,一个 Trace 由一个或多个 TraceSegment 组成,一个 TraceSegment 又由一个或多个 Span 组成。
SpanContext:代表跨越进程上下文,传递到下级 Span 的状态。在 Go 中,通过 context.Context 在同一个服务中进行传递。
Baggage:存储在 SpanContext 中的一个键值对集合。它会在一条追踪链路上的所有 Span 内全局传输,包含这些 Span 对应的 SpanContext。Baggage 会随着 Trace 一同传播。SkyWalking 中,上下文数据通过名为 sw8 的头部项进行传递,值中包含 8 个字段,由 - 进行分割(包括 Trace ID,Parent Span ID 等等)。另外 SkyWalking 中还提供名为 sw8-correlation 的扩展头部项,可以传递一些自定义的信息。
与 Jaeger / Zipkin 相比,虽然都是对 OpenTracing 的实现,但是 ExitSpan、EntrySpan 的概念是在 SkyWalking 中独有的,使用下来体验较好的点在于: 使用语义化的 ExitSpan 和 EntrySpan,使代码逻辑更为清晰;希望逻辑清晰的原因是,有时候创建 Span 确实容易出错,尤其是在对服务链路不熟悉的情况下。所以进行埋点时,对 OpenTracing 的理解是基础,也需要了解服务的链路。

SkyWalking 的插件体系是保障我们得以在一个庞大的微服务架构中进行埋点的基础,官方为 Java、Python、Go、 Node.js 等语言都提供了插件,对 HTTP 框架、SQL、NoSQL、MQ、RPC 等都有插件支持(Java 的插件最为丰富,有 50+,其他语言的插件可能没有这么全面 )。我们基于 Go 和 Python 官方插件的研发思路,又进一步扩展和自制了一些插件,例如:
Go · GORM:GORM 支持为数据库操作注册插件,只需在插件中创建 ExitSpan。
Go · gRPC:利用 gRPC 拦截器,在 metadata(类似 HTTP 的 Header) 中写入上下文。
Go · MQTT:没有找到可以使用的中间件,所以直接写了函数,在发布和收到消息时手动调用。
Python · MQTT:在 Payload 中写入 Carrier(可参考 OpenTracing 中 Baggage 的概念,携带包含 Trace 上下文信息的键值对) 中的上下文数据。
Python · Socket:由于比较底层,按照官方做法自定义 Socket 插件后,HTTP 请求、MQTT 收发消息都会被记录,输出信息过多;所以又自定义了两个函数结合业务手动调用。
前途是光明的,道路是曲折的 —— 记一些我们踩过的坑
由于微服务架构中涉及的语言环境、中间件种类以及业务诉求通常都比较丰富,这导致在接入全链路追踪的过程中难免遇到各种主观和客观的坑,这里给大家介绍几个常见场景。
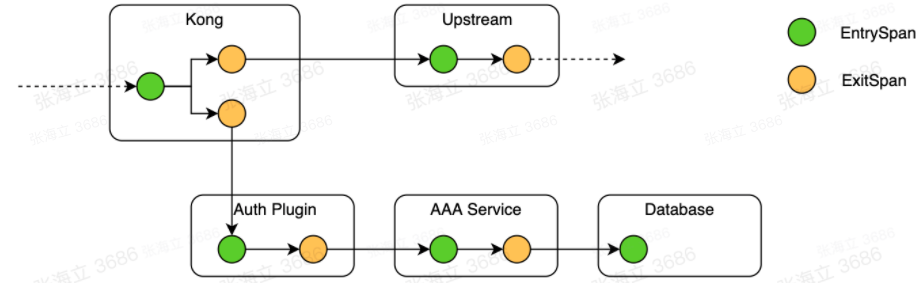
案例一:Kong 网关的插件链路接入问题
找不到官方插件是最常见的一种接入问题。比如我们在接入 SkyWalking 时,官方还未发布 SkyWalking 的 Kong 插件(5 月才发布)。我们因为业务需要在 Kong 中接入了自定义的一个权限插件,用于对 API 和资源的授权;这个插件会调用权限服务的接口进行授权。那么这个插件中的调用,也应属于调用链中的一环,所以我们的解决思路是直接在权限插件中进行了埋点,具体形成的链路如下图所示。
案例二:跨线程/跨进程的链路接入问题
对于跨线程,这里给大家一个提示:可以使用函数 capture() 以及 continued();使用 Snapshot,为 Context 上下文创建快照。对于跨进程,我们遇到一个比较坑的坑是 Python 版本问题:Python 服务中新起一个进程后,原先进程的 SkyWalking Agent 在新进程中无法被使用;需要重新启动一个 Agent 才能正常使用,实践后发现 Python 3.9 可行,Python 3.5 中则会报错 “agent can only be started once”。
案例三:官方 Python Redis 插件 Pub/Sub 断路问题
这个案例是一个典型的官方插件不能覆盖现实业务场景的问题。官方提供的 Python 库中,有提供 Redis 插件;一开始我们认为安装了 Redis 插件,对于一切 Redis 操作,都能互相连接;但是实际上,对于 Pub/Sub 操作,链路是会断开的。
查看代码后发现,对于所有的 Redis 操作,插件都创建一个 ExitSpan。但是在我们的场景中,需要进行 Pub/Sub 操作;这导致两个操作都会创建 ExitSpan,而使链路无法相连。对于这种情况,最后我们通过改造了一下插件来解决问题,大家如果遇到类似情况也需要注意官方插件的功能定位。
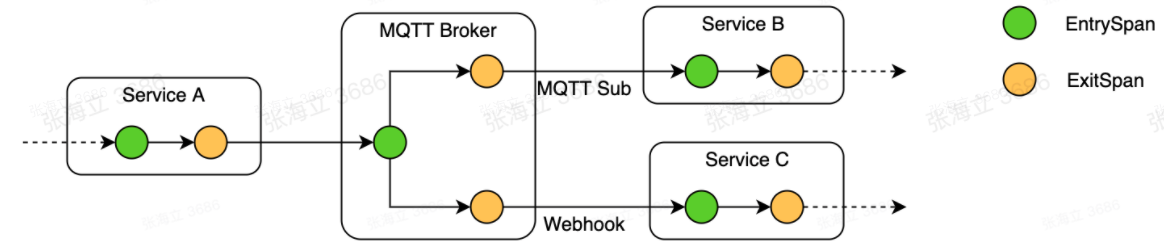
案例四:MQTT Broker 的多种 Data Bridge 接入问题
一般来说,对 MQTT Broker 的追踪链路是 Publisher => Subscriber;但是也存在场景,MQTT Broker 接收到消息后,通过规则引擎调用通知中心的接口;而规则引擎调用接口时,没有办法把 Trace 信息放到 Header 中。
这是一个典型的中间件高级能力未被插件覆盖的问题。通常这种情况还是得就坡下驴,按实际情况做定制。比如这个案例中我们通过约定好参数名称,放到请求体中,在通知中心收到请求后,从请求体中抽取链路的 Context 的方式最终实现了下图的链路贯通。
最后也总结一下我们在 “可观察” 这部分的一些实践体会:首先,还是需要依托一个成熟的持续演进的工具/平台;其次,就是依靠它,同时也要和它一起不断成长、不断自我完善;最后,断路不可怕,伟人说过 “星星之火,可以燎原”,明确目标、坚持努力,一定有机会解决问题的。
KubeSphere 帮助我们快速建立起多集群多租户的 K8s 管理系统,使我们可以高效的管理不同云上的多套生产环境,同时及时掌握其中工作负载的运行状态和性能指标。
驭势科技

未来展望
回首我们这一路和 KubeSphere 携手走来的历程,KubeSphere 已然成为我们日常运维中必不可少的一部分。再次感谢 KubeSphere 团队为中国乃至全球的开源社区贡献了这么一个卓越的云原生产品,我们也希望能尽自己所能多参与社区建设,与 KubeSphere 社区共成长!
我们同时也期盼着 KubeSphere 在后续的版本中提升开放接入外部系统的能力:这样一方面我们可以把内部的一些运维管理系统桥接、挂钩进 KubeSphere 形成统一的一站式的内部运维门户;另一方面也期待更多国内优秀的社区产品和 KubeSphere 形成合力更广泛的服务国内外广大的云原生社区用户。
总之,期待基于 KubeSphere 这个优秀的平台底座,不断建设和打磨 DevOps 闭环,把云原生技术对于云端业务开发的效能提升作用推向极致。

